Contents
This blog post in a paragraph
Why is this C code
5x faster than this equivalent C# code?
On my machine, the C program completes in 32ms versus 150ms for the C# program.
30ms of the difference is due to C# start-up/shutdown overhead. The other 90ms
is due to gcc vectorizing the loop, after being allowed to ignore some
standards around floating-point calculations. This is a very specific case of
numerically-intensive code: it’s not guaranteed that C will always be 5x faster
than C#!
The long story
After making C# go fast, I wondered if I could do much better using a non-managed language like C. Rewriting my game in C is a large project, so I went hunting for smaller examples. Before long, I came across speed comparison, which compares many languages performing the same small calculation of pi. It’s a trivially small piece of code which only compares a tiny portion of what each language is capable of, but it’s a good starting point for a learning exercise.
C comes in at 3 times faster than C# in the above comparison. In this blog post, I’ll investigate why, as someone with a rather patchy understanding of low level code and performance (me).
The questions of which language is the fastest, and whether managed languages like C# are slow have been around forever, and many people smarter than me have written about it online. See appendix B for some interesting reads. The generic reasons given are VM/runtime overhead, garbage collection (GC), just-in-time compilation (JIT), array bounds checking and more. I wasn’t satisfied with generic reasons, and wanted to know specifically why two pieces of comparable code differed.
Running the speed comparison, poking around
Speed comparison is relatively straightforward to run on a Linux-like environment. On my machine, C performed even better than reported, averaging 35ms per run, versus 155ms for C#.
The code:
- reads a number
roundsfrom a file - iteratively calculates the value of pi, looping as many times as
roundsspecifies - prints the value of pi
I tinkered with the code a bit to get an understanding of where the time was
being spent. Eliminating file I/O by hard coding rounds saved a few
milliseconds in both C and C#. Setting rounds to 1 reduced C’s run time to
effectively zero, while C# still took 30ms. I assume this time is
start-up/shutdown time of the C# runtime (CLR), which I don’t particularly care
about.
Out of curiosity, I quickly checked out ahead-of-time compilation (AOT) for C#. It only had a small impact on overall run time, and start-up time was still around 20ms. I didn’t investigate any further.
So: ignoring file I/O and start-up time, C completes the pi calculation in 30ms, while C# takes 120ms. The code for the calculation is almost identical:
C:
for (unsigned i=2u; i < rounds; ++i) {
double x = -1.0 + 2.0 * (i & 0x1);
pi += (x / (2u * i - 1u));
}
C#:
for (int i = 2; i < rounds + 2; i++) {
x *= -1;
pi += (x / (2 * i - 1));
}
Changing the signed-ness of variables and the time at which to increment i
made no difference. The line double x = -1.0 + 2.0 * (i & 0x1); produces the
same value of x as x *= -1, but is important for reasons I’ll talk about
later. First, let’s take a look at the machine code that is generated by C and
C#.
Digging into the machine code
C
To see C disassembly, I used a tool called objdump.
I bypassed Earthly and ran gcc and objdump directly.
The C compilation command in the Earthfile
is:
gcc leibniz.c -o leibniz -O3 -s -static -flto -march=native \
-mtune=native -fomit-frame-pointer -fno-signed-zeros \
-fno-trapping-math -fassociative-math
I modified this slightly to make the objdump output easier to understand:
- removed
-sto keep symbol information - removed
-static, so that external library code was excluded from the executable - added
-gto add debugging information
This didn’t affect the speed of the program.
# compile the program
gcc leibniz.c -o leibniz -O3 -g -flto -march=native \
-mtune=native -fomit-frame-pointer -fno-signed-zeros \
-fno-trapping-math -fassociative-math
# extract the machine code in intel assembly format,
# along with other useful details to help understand
# which part of the code the assembly is for
objdump -drwlCS -Mintel leibniz > leibniz.asm
I’ve put all the assembly together in an appendix.
I’ll cover the gcc options in more detail later. The objdump options are
described here: objdump man page.
C#
Accessing C# disassembly has a much more ‘Windows-y’ feel to it. The most common advice is to use Visual Studio, pause the program at a breakpoint, then access the disassembly via a menu: Debug menu -> Windows -> Disassembly. To make sure you’re looking at optimised code, before running the debugger, you need to disable ‘Suppress JIT optimization on module load’ and ‘Enable Just My Code’ within the menus Tools -> Options -> Debugging -> General.
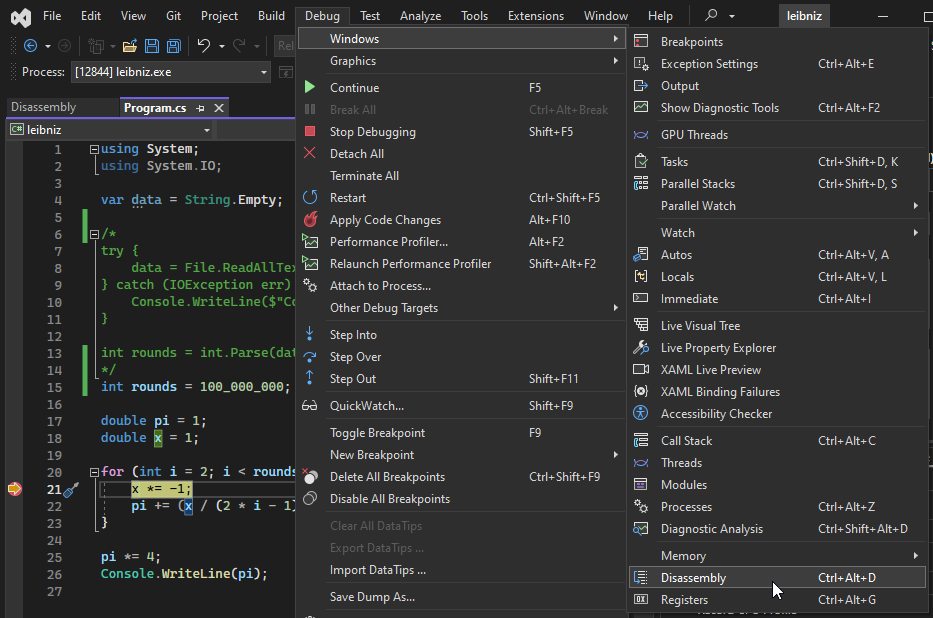
This process makes sense, as .NET executables are distributed in .NET’s intermediate language format (IL), and IL is only compiled to native code by the JIT as needed. 1 2
However, the assembly shown by Visual Studio was suspiciously long compared to the C program’s assembly. With certain compilation settings (more on this later), the C program completed in a similar time to the C# program, yet the C assembly code was less than half as long as the C# disassembly. It didn’t make sense that they could run at the same speed.
This stack overflow answer says
that the JIT behaves differently when run under the debugger. I had a feeling
that this was the case even with the Visual Studio option set to allow JIT
optimization. I tried using vsjitdebugger, spending hours manually stepping
through all the C# runtime start-up until eventually reaching my code, only to
find that it was still the same long set of instructions. If you ever find
yourself needing to use vsjitdebugger, I found that I could only get it to
work by running Visual Studio as admin, then running vsjitdebugger from the
Powershell terminal within Visual Studio.
Eventually, I came across this post about viewing code generated by the JIT. It outlines a number of ways to view the disassembly, one being to use BenchmarkDotNet with DisassemblyDiagnoser. I extracted out the pi calculation to a method, put a benchmark around it, and finally got some assembly code that was comparable to the C program’s assembly.
See the appendix for the C# disassembly.
What does it all mean?
Having the machine code generated from the C and C# code let me do a like for like comparison of each program. I’ve put the assembly code of just the for loops in an appendix at the end of this post.
The first challenge was understanding what all the instructions meant! This quick introduction to x64 assembly (pdf) 3 was a good primer. This x86 reference 4 got me the rest of the way to a basic understanding of what was happening. Rather than decode every instruction and figure out which variables were being stored in which registers, I thought I’d just play around with the C compilation options to get a feel for what changes.
Gcc has many options to control the generated machine code. I’ll summarise the relevant options here. For more details, see gcc’s optimize options 5 and gcc options summary.6
I found that the top contributors to program run time were
-O3 -march=native -fassociative-math -fno-signed-zeros -fno-trapping-math.
O1,O2,O3are shorthand for a collection of optimisation settings,O3being the highest setting-march=native: compile for the host CPU, using any instructions it supports. This is generally only done for numerically intensive code, at the cost of portability. Most widely distributed C programs won’t use this option, as it limits the number of CPUs the program can run on. For more details see this stack overflow question: Why is -march=native used so rarely?-fassociative-math: reorders floating point operations for efficiency, possibly causing underflow / overflow / NaNs-fno-signed-zeros: ignore the sign of zeros-fno-trapping-math: assume that there will be no “division by zero, overflow, underflow, inexact result and invalid operation”
The last three options may cause violations of IEEE or ANSI standards, and are referred to as unsafe math optimizations. I assume this is not necessarily a bad thing, if you know what you’re doing. Indeed, the value of pi calculated with these options varied slightly from the value calculated without them (and by the C# code), but all calculated pi values were still accurate to 7 decimal places.
Using just the -O3 option, the C program took 120ms, which is the same as C#
program, ignoring start-up time. -march=native didn’t make a big difference
unless the unsafe math options were enabled. If you compare the assembly of the
‘unsafe’ and the ‘safe’ options, you can see that the unsafe assembly uses ymm
registers (256 bit registers), allowing more calculations to be done per CPU
instruction. It also only loops 12.5 million times, versus the 100 million times
for the safe assembly. Intuitively, this explains the speedup to me: The unsafe
assembly runs 8x fewer loops, but runs about twice as many instructions per
loop, resulting in a 4x speedup. I don’t know if that’s the exact reason, but
I’m satisfied enough with that answer for now.
Vectorization
What gcc is doing with the unsafe compilation options above is vectorizing the loop. There’s a great explanation of vectorization here: Stack Overflow: What is “vectorization”?. In a sentence, it’s the compiler generating code that executes multiple loop iterations at once, using more efficient CPU instructions.
Gcc was able to automatically vectorize the C code, albeit with the unsafe math
options. The C programmer also needed to know that writing
double x = -1.0 + 2.0 * (i & 0x1) allows the compiler to vectorize, while x *= -1
doesn’t. I didn’t investigate why, but I assume it’s due to the first code
determining the value of x using only the loop counter, while the second code
determines x from the value of x in the previous loop.
It’s also possible to write vectorized code yourself, as demonstrated by the leibniz_avx2.cpp code in speed-comparison. On my machine, this beat the auto-vectorized C by a couple of milliseconds, without needing the unsafe math options. Java and C# also support manual vectorization, however the result in speed-comparison is underwhelming: this vectorized Java code performs 3 times worse than its non-vectorized counterpart! It’d be interesting to see if C# fares any better. Microsoft remarks:
SIMD [vectorization] is more likely to remove one bottleneck and expose the next, for example memory throughput. In general the performance benefit of using SIMD varies depending on the specific scenario, and in some cases it can even perform worse than simpler non-SIMD equivalent code.
The end
So there we have it! For this particular code, C runs 5x faster than C# by relaxing some strict IEEE calculation rules, auto-vectorizing the loop, and having a very low start-up time.
Ignoring start-up time, C# was as fast as standards-compliant C, but vastly outperformed by manually vectorized C++ code. It may be possible to manually vectorize the C# code, but I’ll leave that for a later post.
It’s important to note that the code compared in this post is by no means a fair comparison of the performance of C and C# in general, and there are many more factors to consider when choosing a programming language. Have a look at the links in appendix B for some more perspective.
Appendix A: assembly
Assembly for C and C#. Only the pi calculation loop is shown.
C with unsafe math optimizations: (-O3 -march=native -fassociative-math -fno-signed-zeros -fno-trapping-math, 30ms):
;address: instruction (bytes) instruction (assembly) # my understanding of what's happening
1130: c5 fd 6f c2 vmovdqa ymm0,ymm2 # ymm0 = ymm2
1134: ff c0 inc eax # eax += 1
1136: c5 ed fe d7 vpaddd ymm2,ymm2,ymm7 # ymm2 += (4xi64)ymm7
113a: c5 fd db ce vpand ymm1,ymm0,ymm6 # ymm1 = (4xi64)ymm0 & ymm6
113e: c5 fd 72 f0 01 vpslld ymm0,ymm0,0x1 # ymm0 <<= 1, ie. ymm0 *= 2
1143: c5 fd fe c5 vpaddd ymm0,ymm0,ymm5 # ymm0 += ymm5 (ymm5 = -1?, see 1117)
1147: c5 7e e6 c9 vcvtdq2pd ymm9,xmm1 # (4xi64) ymm9 = (4x double?)xmm1 ... https://www.felixcloutier.com/x86/cvtdq2pd
114b: c4 e3 7d 39 c9 01 vextracti128 xmm1,ymm1,0x1 # xmm1 = ymm1[255:128]
1151: c5 fe e6 c9 vcvtdq2pd ymm1,xmm1 # (4xi64) ymm1 = (4x double?)xmm1
1155: c5 7e e6 d0 vcvtdq2pd ymm10,xmm0 # (4xi64) ymm10 = (4x double?)xmm0
1159: c4 e3 7d 39 c0 01 vextracti128 xmm0,ymm0,0x1 # xmm0 = ymm0[255:128]
115f: c4 62 e5 98 cc vfmadd132pd ymm9,ymm3,ymm4 # (4x double): ymm9 = ymm9 * ymm4 + ymm3
1164: c5 fe e6 c0 vcvtdq2pd ymm0,xmm0 # (4xi64) ymm0 = (4x double?)xmm0
1168: c4 e2 e5 98 cc vfmadd132pd ymm1,ymm3,ymm4 # (4x double): ymm1 = ymm1 * ymm4 + ymm3
116d: c4 41 35 5e ca vdivpd ymm9,ymm9,ymm10 # ymm9 /= ymm10
1172: c5 f5 5e c0 vdivpd ymm0,ymm1,ymm0 # ymm0 = ymm1/ymm0
1176: c5 b5 58 c0 vaddpd ymm0,ymm9,ymm0 # ymm0 += ymm9
117a: c5 3d 58 c0 vaddpd ymm8,ymm8,ymm0 # ymm8 += ymm0
117e: 3d 20 bc be 00 cmp eax,0xbebc20 # if eax != 12500000 (=100M/8)
1183: 75 ab jne 1130 <main+0x90> # goto 1130
Safe C (-O3 -march=native, 120ms):
;address: instruction (bytes) instruction (assembly) # my understanding of what's happening
1120: 89 c1 mov ecx,eax # ecx = eax
1122: c5 e3 2a d2 vcvtsi2sd xmm2,xmm3,edx # xmm2 = (double)edx? https://www.felixcloutier.com/x86/cvtsi2sd
1126: ff c0 inc eax # eax += 1
1128: 83 c2 02 add edx,0x2 # edx += 2
112b: 83 e1 01 and ecx,0x1 # ecx &= 1
112e: c5 e3 2a c9 vcvtsi2sd xmm1,xmm3,ecx # xmm1 = (double)ecx?
1132: c4 e2 d9 99 cd vfmadd132sd xmm1,xmm4,xmm5 # xmm1 = xmm1 * xmm5 + xmm4
1137: c5 f3 5e ca vdivsd xmm1,xmm1,xmm2 # xmm1 /= xmm2
113b: c5 fb 58 c1 vaddsd xmm0,xmm0,xmm1 # xmm0 += xmm1
113f: 3d 02 e1 f5 05 cmp eax,0x5f5e102 # if eax != 100M+2
1144: 75 da jne 1120 <main+0x80> # goto 1120
C# (BenchmarkDotNet):
M01_L00:
; instruction params # my understanding
vmulsd xmm0,xmm0,xmm2 # xmm0 *= xmm2
lea edx,[rax*2-1] # edx = *(rax*2-1)
vxorps xmm3,xmm3,xmm3 # xmm3 = 0
vcvtsi2sd xmm3,xmm3,edx # xmm3 = (double)edx
vdivsd xmm3,xmm0,xmm3 # xmm3 = xmm0 / xmm3
vaddsd xmm1,xmm3,xmm1 # xmm1 = xmm3 + xmm1
inc eax # eax += 1
cmp eax,5F5E102 # if eax < 100M+2
jl short M01_L00 # goto M01_L00
C# (Visual Studio, not optimised):
;address instruction (assembly) # my understanding of what's happening
00007FFF1835417B vmovsd xmm0,qword ptr [rbp-48h] # xmm0 = *(rbp-48h)
00007FFF18354180 vmulsd xmm0,xmm0, # xmm0 = xmm0 * *(07FFF18354210) mmword ptr [Program.<<Main>$>g__CalcPi|0_0()+0E0h (07FFF18354210h)]
00007FFF18354188 vmovsd qword ptr [rbp-48h],xmm0 # *(rbp-48h) = xmm0
00007FFF1835418D vmovsd xmm0,qword ptr [rbp-48h] # xmm0 = *(rbp-48h)
00007FFF18354192 mov eax,dword ptr [rbp-4Ch] # eax = *(rbp-4Ch)
00007FFF18354195 lea eax,[rax*2-1] # eax = *(rax*2-1)
00007FFF1835419C vxorps xmm1,xmm1,xmm1 # xmm1 = 0
00007FFF183541A0 vcvtsi2sd xmm1,xmm1,eax # xmm1 = (double)eax? https://www.felixcloutier.com/x86/cvtsi2sd
00007FFF183541A4 vdivsd xmm0,xmm0,xmm1 # xmm0 /= xmm1
00007FFF183541A8 vaddsd xmm0,xmm0,mmword ptr [rbp-40h] # xmm0 += *(rbp-40h)
00007FFF183541AD vmovsd qword ptr [rbp-40h],xmm0 # *(rbp-40h) = xmm0
00007FFF183541B2 mov eax,dword ptr [rbp-4Ch] # eax = *(rbp-4Ch)
00007FFF183541B5 inc eax # eax += 1
00007FFF183541B7 mov dword ptr [rbp-4Ch],eax # *(rbp-4Ch) = eax
00007FFF183541BA mov ecx,dword ptr [rbp-58h] # ecx = *(rbp-58h)
00007FFF183541BD dec ecx # ecx -= 1
00007FFF183541BF mov dword ptr [rbp-58h],ecx # *(rbp-58h) = ecx
00007FFF183541C2 cmp dword ptr [rbp-58h],0 # if *(rbp-58h) > 0
00007FFF183541C6 jg # goto 07FFF183541D6 Program.<<Main>$>g__CalcPi|0_0()+0A6h (07FFF183541D6h)
00007FFF183541C8 lea rcx,[rbp-58h] # rcx = *(rbp-58h)
00007FFF183541CC mov edx,33h # edx = 51
00007FFF183541D1 call 00007FFF77D8C9B0 # call mystery function. appears to be JIT related
00007FFF183541D6 cmp dword ptr [rbp-4Ch],5F5E102h # if *(rbp-4Ch) < 100M +2
00007FFF183541DD jl # goto 07FFF1835417B
Appendix B: Interesting reading
- Is C# slower than say C++?
- detailed generic answer
- covers language features, VM, GC, benchmarks
- conclusion: you can almost always write C/C++ that’s faster than C#, but not the other way around
- specific case answer
- yes, but it may take a C++ expert significant time to make it run faster than C#
- detailed generic answer
- Jeff Atwood: The bloated world of Managed Code
- C# cons: slower, uses more memory
- C# pros: faster development
- Jeff Atwood: On Managed Code Performance
- C# pro: security: buffer overruns possible in C/C++ can’t happen in C#
- quake 2 .NET port was initially faster than the C version, but 15% slower after C targeted the host CPU, and 30% slower than the hand-optimised assembly version